 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Holistic Models: Systematic Component-level Benchmarking of Deep Multivariate Time-Series Forecasting
May 26, 2026While previous research in multivariate time series forecasting has focused on developing complex holistic models, this work advocates for a shift toward a granular, component-level understanding of their impacts. We propose TSCOMP, the first large-scale benchmark that systematically deconstructs deep forecasting methods into their core, fine-grained components--spanning series preprocessing, encoding strategies, network architectures including specific and large time-series models, and optimization methods. Using constrained orthogonal experimental design and extensive evaluations, we conduct multi-view analyses that reveal component effectiveness across different backbones, data characteristics, and their interactions. Beyond providing insights, this benchmark establishes a fine-grained performance corpus comprising over 20,000 model-dataset evaluations, which supports the learning of automated component selection, enabling zero-shot model construction on new datasets. Our experiments demonstrate that the corpus-driven approach, despite its simplicity, consistently outperforms state-of-the-art methods, validating the soundness of our evaluation design and confirming that systematic component selection surpasses manually designed complex architectures. All code and the performance corpus are publicly available at https://github.com/SUFE-AILAB/TSCOMP.
Rethinking Weak Supervision in Anomaly Detection: A Comprehensive Benchmark
May 26, 2026Weakly supervised anomaly detection (WSAD) has developed in three primary directions: incomplete, inexact, and inaccurate supervision. However, these directions remain isolated, lacking a unified framework to assess whether they address unique challenges or share fundamental mechanics. This paper introduces WSADBench, the first benchmark that unifies evaluation across distinct weakly supervised scenarios, benchmarking diverse approaches from specialized WSAD methods to advanced tabular foundation models. WSADBench establishes standardized protocols to evaluate 36 algorithms across 4 modalities by systematically varying label quantity, granularity, and quality, revealing the performance boundaries of various methods. Based on over 700K experiments, WSADBench reveals four critical insights: (i) Strong intrinsic correlations exist between these weak supervision scenarios, challenging the isolation of current research directions. (ii) Specialized WSAD algorithms excel only in extreme label-scarcity regimes but are quickly dominated by tabular foundation models and general classification methods as supervision increases or in OOD scenarios. (iii) Unlabeled data shows inconsistent utility across settings, with marginal gains compared to label refinement. (iv) Models exhibit asymmetric sensitivity to different types of label noise. We release WSADBench as an open-source benchmark with code and datasets to facilitate future WSAD research: https://github.com/SUFE-AILAB/WSADBench.
An Effective Data Augmentation Method by Asking Questions about Scene Text Images
Mar 03, 2026Scene text recognition (STR) and handwritten text recognition (HTR) face significant challenges in accurately transcribing textual content from images into machine-readable formats. Conventional OCR models often predict transcriptions directly, which limits detailed reasoning about text structure. We propose a VQA-inspired data augmentation framework that strengthens OCR training through structured question-answering tasks. For each image-text pair, we generate natural-language questions probing character-level attributes such as presence, position, and frequency, with answers derived from ground-truth text. These auxiliary tasks encourage finer-grained reasoning, and the OCR model aligns visual features with textual queries to jointly reason over images and questions. Experiments on WordArt and Esposalles datasets show consistent improvements over baseline models, with significant reductions in both CER and WER. Our code is publicly available at https://github.com/xuyaooo/DataAugOCR.
VideoSPatS: Video SPatiotemporal Splines for Disentangled Occlusion, Appearance and Motion Modeling and Editing
Apr 08, 2025



We present an implicit video representation for occlusions, appearance, and motion disentanglement from monocular videos, which we call Video SPatiotemporal Splines (VideoSPatS). Unlike previous methods that map time and coordinates to deformation and canonical colors, our VideoSPatS maps input coordinates into Spatial and Color Spline deformation fields $D_s$ and $D_c$, which disentangle motion and appearance in videos. With spline-based parametrization, our method naturally generates temporally consistent flow and guarantees long-term temporal consistency, which is crucial for convincing video editing. Using multiple prediction branches, our VideoSPatS model also performs layer separation between the latent video and the selected occluder. By disentangling occlusions, appearance, and motion, our method enables better spatiotemporal modeling and editing of diverse videos, including in-the-wild talking head videos with challenging occlusions, shadows, and specularities while maintaining an appropriate canonical space for editing. We also present general video modeling results on the DAVIS and CoDeF datasets, as well as our own talking head video dataset collected from open-source web videos. Extensive ablations show the combination of $D_s$ and $D_c$ under neural splines can overcome motion and appearance ambiguities, paving the way for more advanced video editing models.
Smart Audit System Empowered by LLM
Oct 10, 2024



Manufacturing quality audits are pivotal for ensuring high product standards in mass production environments. Traditional auditing processes, however, are labor-intensive and reliant on human expertise, posing challenges in maintaining transparency, accountability, and continuous improvement across complex global supply chains. To address these challenges, we propose a smart audit system empowered by large language models (LLMs). Our approach introduces three innovations: a dynamic risk assessment model that streamlines audit procedures and optimizes resource allocation; a manufacturing compliance copilot that enhances data processing, retrieval, and evaluation for a self-evolving manufacturing knowledge base; and a Re-act framework commonality analysis agent that provides real-time, customized analysis to empower engineers with insights for supplier improvement. These enhancements elevate audit efficiency and effectiveness, with testing scenarios demonstrating an improvement of over 24%.
Enhancing Molecular Property Prediction via Mixture of Collaborative Experts
Dec 06, 2023



Molecular Property Prediction (MPP) task involves predicting biochemical properties based on molecular features, such as molecular graph structures, contributing to the discovery of lead compounds in drug development. To address data scarcity and imbalance in MPP, some studies have adopted Graph Neural Networks (GNN) as an encoder to extract commonalities from molecular graphs. However, these approaches often use a separate predictor for each task, neglecting the shared characteristics among predictors corresponding to different tasks. In response to this limitation, we introduce the GNN-MoCE architecture. It employs the Mixture of Collaborative Experts (MoCE) as predictors, exploiting task commonalities while confronting the homogeneity issue in the expert pool and the decision dominance dilemma within the expert group. To enhance expert diversity for collaboration among all experts, the Expert-Specific Projection method is proposed to assign a unique projection perspective to each expert. To balance decision-making influence for collaboration within the expert group, the Expert-Specific Loss is presented to integrate individual expert loss into the weighted decision loss of the group for more equitable training. Benefiting from the enhancements of MoCE in expert creation, dynamic expert group formation, and experts' collaboration, our model demonstrates superior performance over traditional methods on 24 MPP datasets, especially in tasks with limited data or high imbalance.
Video Coding Using Learned Latent GAN Compression
Jul 12, 2022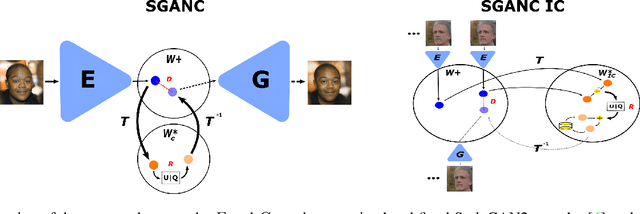

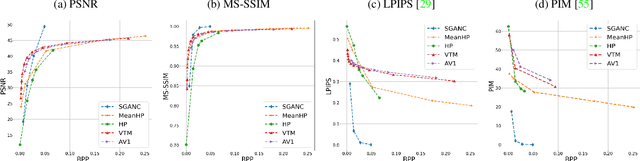

We propose in this paper a new paradigm for facial video compression. We leverage the generative capacity of GANs such as StyleGAN to represent and compress a video, including intra and inter compression. Each frame is inverted in the latent space of StyleGAN, from which the optimal compression is learned. To do so, a diffeomorphic latent representation is learned using a normalizing flows model, where an entropy model can be optimized for image coding. In addition, we propose a new perceptual loss that is more efficient than other counterparts. Finally, an entropy model for video inter coding with residual is also learned in the previously constructed latent representation. Our method (SGANC) is simple, faster to train, and achieves better results for image and video coding compared to state-of-the-art codecs such as VTM, AV1, and recent deep learning techniques. In particular, it drastically minimizes perceptual distortion at low bit rates.
Semantic Unfolding of StyleGAN Latent Space
Jun 29, 2022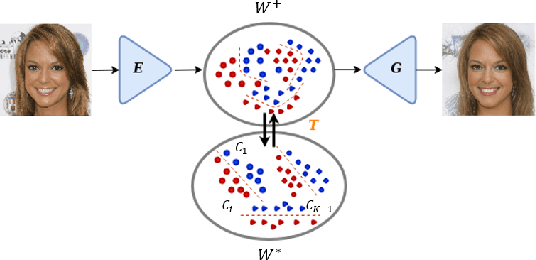
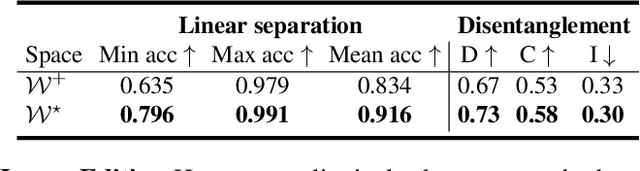

Generative adversarial networks (GANs) have proven to be surprisingly efficient for image editing by inverting and manipulating the latent code corresponding to an input real image. This editing property emerges from the disentangled nature of the latent space. In this paper, we identify that the facial attribute disentanglement is not optimal, thus facial editing relying on linear attribute separation is flawed. We thus propose to improve semantic disentanglement with supervision. Our method consists in learning a proxy latent representation using normalizing flows, and we show that this leads to a more efficient space for face image editing.
Feature-Style Encoder for Style-Based GAN Inversion
Feb 04, 2022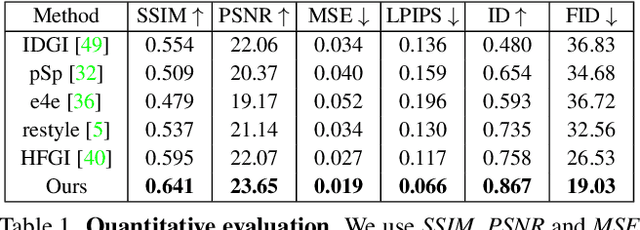
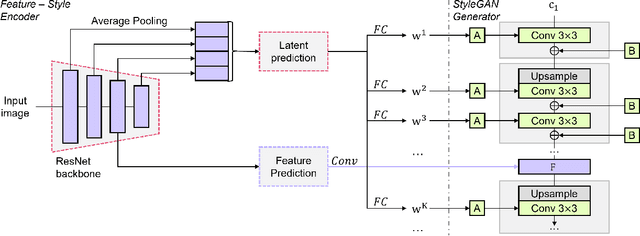
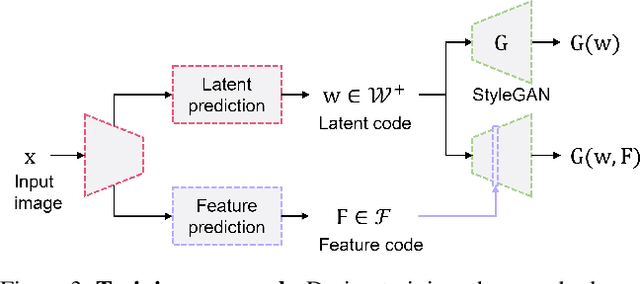
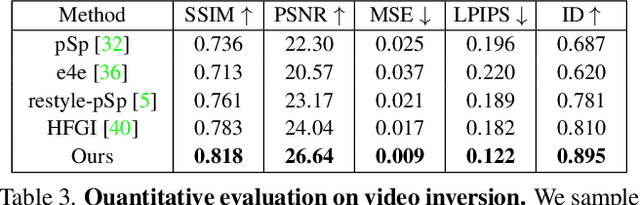
We propose a novel architecture for GAN inversion, which we call Feature-Style encoder. The style encoder is key for the manipulation of the obtained latent codes, while the feature encoder is crucial for optimal image reconstruction. Our model achieves accurate inversion of real images from the latent space of a pre-trained style-based GAN model, obtaining better perceptual quality and lower reconstruction error than existing methods. Thanks to its encoder structure, the model allows fast and accurate image editing. Additionally, we demonstrate that the proposed encoder is especially well-suited for inversion and editing on videos. We conduct extensive experiments for several style-based generators pre-trained on different data domains. Our proposed method yields state-of-the-art results for style-based GAN inversion, significantly outperforming competing approaches. Source codes are available at https://github.com/InterDigitalInc/FeatureStyleEncoder .
Semantic and Geometric Unfolding of StyleGAN Latent Space
Jul 09, 2021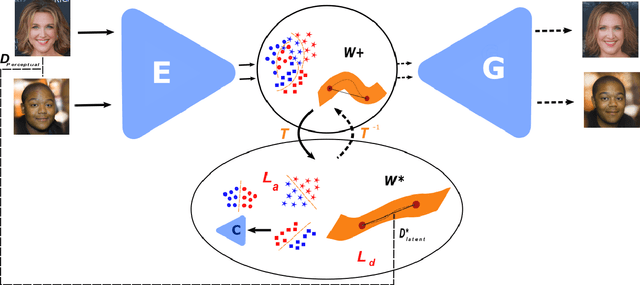
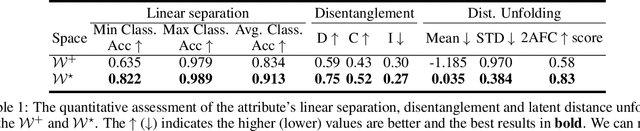

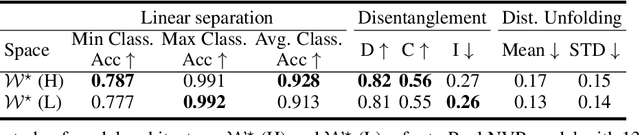
Generative adversarial networks (GANs) have proven to be surprisingly efficient for image editing by inverting and manipulating the latent code corresponding to a natural image. This property emerges from the disentangled nature of the latent space. In this paper, we identify two geometric limitations of such latent space: (a) euclidean distances differ from image perceptual distance, and (b) disentanglement is not optimal and facial attribute separation using linear model is a limiting hypothesis. We thus propose a new method to learn a proxy latent representation using normalizing flows to remedy these limitations, and show that this leads to a more efficient space for face image editing.